Sequence는 연속된 데이터의 집합.
-순서: 시퀀스 내의 각 요소는 순서를 가진다.
-변동성: 시퀀스의 길이는 고정되어 있지 않고 변할 수 있다.
-연관성: 시퀀스 내의 요소들은 서로 연관되어 있을 수 있고, 이 연관성을 모델링 하기!
그러니까 자연어에서는 문장이나 문서 (단어나 문자로 이루어진 연속적인 데이터)
seq2seq은 입력된 시퀀스로부터 다른 시퀀스를 출력하는 모델
예를 들어 챗봇, 기계 번역, 요약 이런거
1. 모델의 개요
' Sequence to Sequence Learning with Neural Networks' 여기서 처음 나온 개념인데,
RNN을 기반으로 한 인코더-디코더 모델을 사용해 시퀀스를 입력으로 받아 다른 시퀀스를 출력하는 방법을 소개했다
seq2seq 모델은 인코더와 디코더로 구성되어있다.
인코더는 입력 문장의 모든 단어를 순차적으로 받은 뒤, 모든 정보를 압축해서 하나의 벡터 (context vector)로 만든다.
디코더는 context vector를 받아서 단어를 하나씩 순차적으로 출력한다.
2. seq2seq 동작 과정
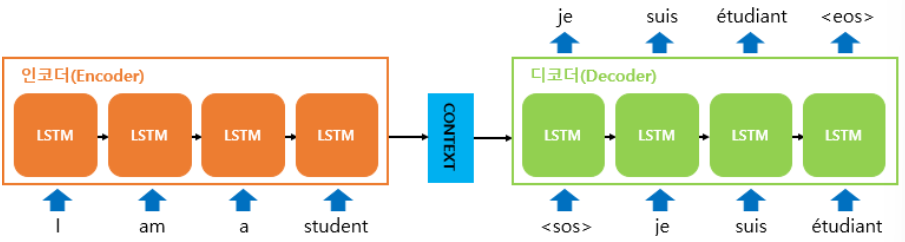
입력 문장을 받는 RNN cell을 인코더, 출력 문장을 출력하는 RNN cell을 디코더라고 한다.
성능 문제로 vanilla RNN말고 LSTM, GRU cell들로 구성한다.
인코더에서는 RNN/LSTM 원리랑 같음
첫 번째 cell에선 input으로 단어 받고 hidden state 계산
>다음 cell에선 input으로 단어 받고, 이전 hidden state 받아서 hidden state 계산 (시그모이드나 탄젠트)
이거 반복해서 마지막 cell이 만든 hidden state= context vector
디코더로 전달하면
첫 번째 cell에선 input으로 <sos>, 이전 hidden state로 context vector 받아서 hidden state 계산하고 다음 단어 출력
>다음 cell에선 input으로 이전 예측 단어, 이전 hidden state 받고 또 계산해서 예측 단어 출력
>마지막 cell에선 <eos> 출력 그럼 끝
각 cell에선 hidden state로 출력 벡터 계산(dense) > softmax로 단어별 확률값 반환하고 출력 단어 결
근데 학습할 땐 빠르게 하려고 input으로 이전 예측 단어 안쓰고 정답 단어를 쓰기도 함. 그럼 학습 속도는 빠른데 실제 환경과 좀 떨어진다는게 약간 오버피팅 느낌으로 이해하면 되나?
아니엇음 ;;
학습-추론 간 불일치 문제 (Exposure Bias) 때문임: 실제 inference 때는 정답 단어를 알 수 없는데, 학습은 항상 정답 기준으로 되어 있어서 추론 시 오류가 누적될 수 있음
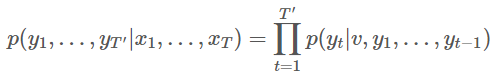
입력 시퀀스 x 가지고 출력 시퀀스 y를 생성
v는 context vector
좌변은 x들 (입력 문장) 들어왔을 떄 y들 (출력 문장)에 대한 조건부 확률
우변은 t 시점의 y 단어 생성 위해 v, 이전 y들이 입력되는거> 소프트맥스로 저렇게 표현
이거 다 곱하면 좌변 되는거고
seq2seq의 주요 문제점
1. 장기 의존성 문제: 긴 문장에선 초기 입력 정보가 나중에 영향 미치기 어려워서 정보 소실될수도
gradient vanishing 같은거로 생김
LSTM이 이걸 다 극복한건 아니었음
2. 단일 컨텍스트 벡터: 모든 정보를 벡터 하나에 넣으니까 정보 손실
3. 시퀀스 길이 제한
그래서 나온건 attention 메커니즘
Attention mechanism
attention은 디코더에서 출력 단어를 예측하는 매 step마다 인코더에 있는 전체 입력 문장을 현재 시점에서 예측해야할 단어와 연관이 있는 입력 단어를 더 attention해서 보는것
Attention(Q, K, V) = Attension Value
Q= query : t 시점의 디코더에서의 hidden state
K=keys : 모든 시점의 인코더 셀의 hidden state
V=values : 모든 시점의 인코더 셀의 hidden state
주어진 Query에 대해서 모든 key와의 유사도를 각각 구하고 이 유사도를 key와 매핑되어있는 각각의 값에 반영해주고 유사도가 반영된 value를 모두 더해서 return한게 attention value
```
Q와 K의 유사도(점곱) 계산 → softmax → V에 가중 평균 → context vector
Dot-Product Attention
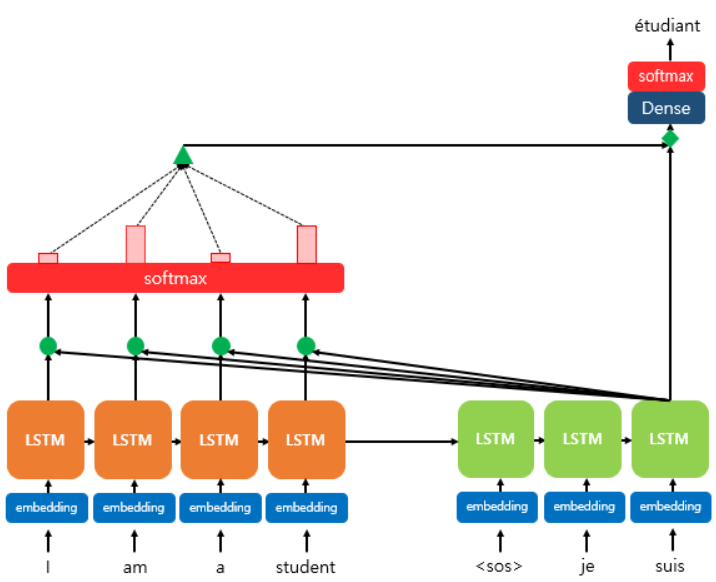
encoder의 softmax 함수를 사용하는 것이 메인 아이디어.
1. Attetion Score 구하기
: encoder의 hidden state들과 지금 시점 decoder의 hidden state 벡터 사이의 유사도를 계산 (점곱, 제곱차, 코사인 유사도 등등 많음)
여기선 점 곱을 사용.
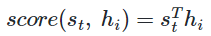
t에서의 decoder의 hidden state를 St
i번째 encoder의 i번째 hidden state를 hi
St와 encoder의 i 번째 hidden state 의 attention score계산 ~
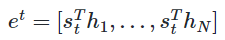
이걸 모든 encoder랑 다 한거
2. Softmax 함수를 통해 attention distribution 구하기
: 유사도를 정규화하기 위해 Softmax 함수 적용 이게 가중치가 됨
attention distribution: et를 소프트맥스 함수에 적용해 합이 1 되는 확률 분포 얻음

디코더 시점 t에서의 어텐션 분포
3. 각 encoder의 attention weight와 hidden state를 weighted sum 해서 attention value 구하기
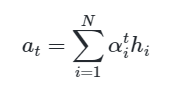
가중 평균 낸게 attention value고 이걸 context vector라고도 부름
4. attention value랑 decoder t시점의 hidden state 연결
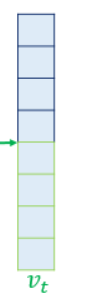
hidden state에 이어 붙여서 새로운 벡터 생성
5. 출력층 연산이 입력이 되는 새로운 st 계산

위에서 만든 벡터는 tanh 지남.
-비선형성 위해
-(-1, 1) 사이로 출력 스케일 조정
6. 저 st를 출력층의 입력으로 사용

어텐션 단점: 계산 비용, 모델 복잡성, 특정 상황에서는 입력 전체가 아니라 일부만 집중적으로 처리하는게더 효과적일 수 있다.
어텐션 종류가 많긴한데 바다나우 어텐션은 나중에 쓸래
'인공지능 공부' 카테고리의 다른 글
| [논문 리뷰] DeepSeek-R1: Incentivizing Reasoning Capanility in LLMs via Reinforcement Learning (1) | 2025.06.20 |
|---|---|
| 미루고 미루던 강화학습 (4) | 2025.06.20 |
| 인공지능의 알파이자 오메가 (0) | 2025.05.15 |
| vLLM을 GPU에 띄운다. (0) | 2025.05.15 |
| RAG 정리하기 (0) | 2025.05.15 |