
https://arxiv.org/html/2507.16003v1
Learning without training: The implicit dynamics of in-context learning
At a high-level, similar to [6], we train a simple transformer on instances of prompts of input-output pairs of the form (x1,h(x1),…,xN,h(xN),xquery)subscript𝑥1ℎsubscript𝑥1…subscript𝑥𝑁ℎsubscript𝑥𝑁subscript𝑥query(x_{1},h(x
arxiv.org
대기업에서 엄청나게 큰 모델을 가져다가 구조화된 프롬프트만 맥여서 사용하는 게 거의 보편적인 방법이 되었다.
모두가 굳이 비싼 비용과 시간을 들여서 학습을 할 필요가 없다는 것이다.
근데 이게 어떻게 되냐? 하는 내용을 구글 리서치에서 논문으로 냈어요.
아래는 세 줄 요약
- 프롬프트를 넣는다는 건, 실제로 가중치를 바꾸지는 않지만, 마치 바뀐 것처럼 모델이 다르게 동작하게 만든다.
- 왜 그렇게 말하냐면, context를 넣은 출력값과, weight를 업데이트한 후 출력값이 거의 동일하다는 걸 수식과 실험으로 확인했기 때문이다.
- 결국, context가 바꾼 입력을 MLP에 넣는 것과, 그 context의 영향을 반영해 MLP 가중치를 바꾼 후 입력을 넣는 것이 동일한 결과를 낸다.
LLM은 어떻게 학습 없이도 프롬프트만으로 새로운 태스크를 잘 수행할 수 있을까?
이것은 in context learning(ICL)이라고 부르고
기존 연구들은 이 현상을 주로 transformer가 내부적으로 gradient descent를 흉내낸다고 가정했다. 즉 일종의 암묵적인 메타학습이 발생한다고 가정했다.
실제고 간단한 회귀 문제를 다룬 toy model에서는 이론적으로 이게 가능하다는 결과가 나왔지만, 너무 단순한 조건에만 적용된다.
- linear attention 만 사용 (근데 LLM은 멀티헤드, 논리니어임)
- 회귀 함수만 포함된 간단한 프롬프트 실험
- 실험 대상이 작은 transformer 모델이었음
그래서 실제 gpt같은 LLM에서 ICL은 어떤 구조로 가능한가 ~~를 또 구글 리서치에서 냄 (preprint임, 아직 리뷰x)
제안한 방법론? 가정? 전제 및 수학적 단순화 ..?
핵심 아이디어는 아래와 같다.
: Transformer의 self-attention + MLP 구조는, 프롬프트(context)를 마치 MLP 가중치를 살짝 수정(fine-tune)한 것처럼 행동하게 만든다.
그니까, 프롬프트 넣는 것만으로도 MLP 레이어 가중치가 암묵적으로 업데이트 되는 것처럼 동작한다는 것이다.
업데이트 되면 업데이트 되는 것이지, “암묵적으로 업데이트되는 것처럼 동작”은 뭔소리냐 …
일단 얘를 수학적으로 분석하기 위해서, Contextual Block을 정의한다.
- Contextual Block = Contextual Layer (ex. self-attention) + MLP의 조합
- 여기서 self-attention이 문맥을 받아서 입력을 바꾸는 역할이라면
- MLP는 그 바뀐 조합을 처리하는 구조인데
- 이 전체 조합이 결과적으로 MLP 가중치를 context에 따라 바꾼 것과 동일한 효과를 낸다는 것이 주장 ~~~~~~~~~~
구체적으로, context가 길어질수록 MLP의 weight matrix W 에 저랭크(rank-1) 업데이트가 반복적으로 일어나고, 이는 gradient descent와 비슷한 학습 dynamics를 만들어낸다고 설명한다.
업데이트는 아래 수식

- △A는 context가 있든 없든 self attention에서 나오는 벡터의 차이.
- 즉 self attention이 어떻게 출력 벡터를 바꾸는지를 포착한 값
실험 결과: 진짜 되냐
실험에서는 선형 함수를 예측하는 간단한 문제를 정의한다.(근데 기존 실험들이 간단한 선형 함수 예측한거로 비판하고 지는 왜 이거함?)
transformer에게 여러 input output 쌍을 prompt로 주고, 새로운 입력 x에 대해
h(x)≈⟨w,x⟩ 이걸 예측하는 문제임.
그리고 비교
- 프롬프트를 직접 입력으로 넣은 transformer (기존 방식)
- 프롬프트는 없지만, 해당 프롬프트로부터 계산한 △W로 MLP 가중치 수정한 transformer
당연히 둘이 예측 성능이 거의 동일하게 나왔으니까 논문을 냈겠죠.
즉~ 프롬프트를 넣는 것과 MLP 가중치를 △W로 조정하는 것이 동일한 효과를 가진다. (특정 조건 하에서는)
+프롬프트 하나 추가할 때마다 △W가 조금씩 바뀌다가 점점 수렴하는 경향도 보임.
:마치 online gradient descent처럼 반복적으로 weight가 갱신되다가 안정화되는 학습 과정과 유사하다는 것.
+fine-tuning (실제 gradient descent로 MLP weight를 바꾸는 것)과 비교해도, 성능 변화 양상이 유사하게 나타남.
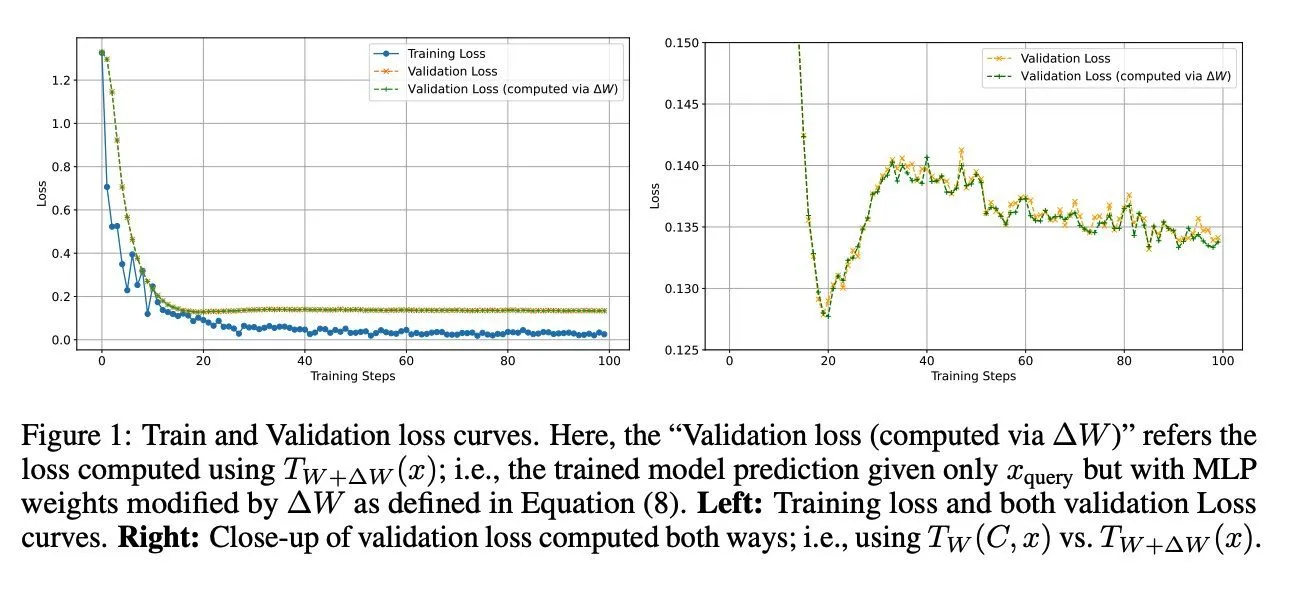
결론: 진짜 weight update든, 암묵적인 update든, 둘 다 loss를 잘 줄여가며 학습처럼 행동하고 있다는 것
한계점은여?
- Transformer 전체가 아니라 단일 block만 분석:
- 이론은 한 개의 transformer block 내에서만 성립
- 실제 LLM은 여러 block으로 구성되어 있으므로, 전체 동작을 설명하려면 추가 분석이 필요할 것
- 토큰 전체가 아닌 "첫 번째 출력만" 분석:
- 이 논문은 context를 입력으로 넣었을 때 나오는 첫 번째 예측 결과만 해석할 수 있다.
- 이후 토큰을 생성하면서 어떻게 변화가 누적되는지에 대해서는 설명이 부족하다.
- 복잡한 자연어 처리 문제에는 아직 적용되지 않음:
- 여전히 실험은 선형 함수 예측이라는 간단한 세팅에서 진행되며, 복잡한 문장이나 논리 추론 등에는 적용x
물론 이론적 전개나 실험이 깔끔하긴 하지만, 이걸 바로 GPT나 PaLM 같은 실제 LLM의 전체 동작으로 일반화할 수는 없다.
다층 구조, multi-token generation, 다양한 자연어 태스크에서는 아직 추가 연구가 필요하다.
그럼 20000