베이지안 통계학 !
통계학 부전공을 하며 전공 선택 과목을 고를 때,
- 재밌어보이지만 어렵고, 소수 정예라 학점 방어가 빡센 과목 vs.
- 고만고만하게 듣고 사람 많은 과목
중에서 대학 4년 다니는데 내가 해보고 싶은거 들어봐야지 하며 전자를 택했습니다.
그게 바로 베이지안 통계학이었어요.
이 수업은 실습이 적고 판서 위주로 수업이 진행되어서, 막 통계에 입문한 저에게는 되게 흥미롭고 신기하지만 와닿지 않는 .. 되게 철학적인 과목이라는 느낌을 받았어요.
하지만 인공지능을 깊게 다루다 보니, 수많은 모델과 알고리즘의 뼈대에 베이즈 정리가 놓여 있더군요.
이 글은 그 경험에서 출발해, 베이지안 vs 빈도론, 그리고 AI에서 왜 베이지안이 이렇게 자주 쓰이는지를 정리합니다.
1) 베이지안 vs 빈도론: 관점의 차이
우리가 확률과 통계 시간에 배운건 모두 빈도주의 입니다.
- 빈도주의(Frequentist): 모수 θ는 고정된 미지의 값. 데이터는 반복 표본추출될 수 있다고 가정.
대표: MLE, 점추정, 신뢰구간(빈도적 해석). - 베이지안(Bayesian): 모수 θ를 확률변수로 모델링.
나의 믿음을 확률로 표현하며 .. 사전확률을 데이터를 관측 한 후의 사후 확률로 업데이트하며 찾아가요
베이즈 정리
이 한 줄 수식에서 모두 나옵니다.
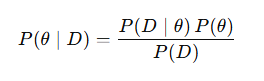
- P(θ): 사전분포(prior) — 데이터 보기 전, θ에 대한 믿음
- P(D∣θ): 가능도(likelihood) — 주어진 θ에서 데이터가 나올 확률
- P(θ∣D): 사후분포(posterior) — "데이터 관찰 후", θ에 대한 갱신된 믿음
- P(D): evidence (정규화 상수)
핵심: 베이지안은 “불확실성 전체”를 분포로 관리한다는 점에서, 결정과 리스크관리와의 접점이 강합니다.
2) 베이지안의 장단점
장점
- 불확실성 정량화: 점추정이 아니라 분포 전체를 제공 → 신뢰구간/예측구간/캘리브레이션.
- 소표본/희귀 이벤트: prior로 도메인지식 주입 가능.
- 결정이론과 결합: 손실 L(y,y^)에 대한 사후기대손실 최소화로 비용민감 의사결정.
단점/논쟁점
- Prior 주관성: 잘 쓰면 힘이 되지만, 잘못 쓰면 편향. (정규 사전 vs 비정보적 사전 등 선택 이슈)
- 계산비용: 정확 posterior는 어려워서 MCMC/VI 등 근사가 필요.
- 조직 문화: 빈도주의 전통이 강한 도메인에선 해석 저항.
결론: 비용·리스크가 큰 문제, 데이터가 적거나 분포가 흔들리는 문제, 정책적 책임/감사가 필요한 문제일수록 베이지안의 가치가 커집니다.
그런데도 불구하고, 인공지능 분야에서는 아주 자주 볼 수 있어요. 베이지안 xxx이면 당연히 베이지안이고, 마르코프 체인 XXX 얘네도 다 베이지안이에요. 왜케 많이 쓰일까요?
3) AI에서 왜 베이지안이 이렇게 자주 쓰일까?
딥러닝은 보통 “숫자 하나”를 냅니다. 예: “이 환자는 질병일 확률 0.87”
하지만 그 0.87이 정말 확신인지, 아니면 데이터가 빈약해서 생긴 불확실성인지는 별개 문제죠.
베이지안은 여기서 Epistemic(모델) vs Aleatoric(자료) 불확실성을 구분·정량화합니다.
4) 그리고 불확실성의 두 종류
- Aleatoric(자료 고유의 잡음, 비가역·비감소)
- Epistemic(모델/파라미터 불확실성, 데이터 늘리면 감소)
- 예측분산 분해(회귀):
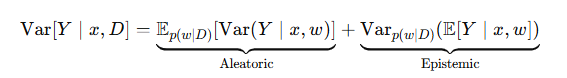
분류에서는 Predictive Entropy와 BALD(I[y,w∣x,D])로 유사하게 본질을 분리합니다.
4) 핵심 응용 — 디테일 확장판
일단 계속 나올 D는 데이터셋 전체예요.
(1) 베이지안 신경망 (Bayesian Neural Networks, BNN)
- 아이디어: 신경망 가중치 w에 대해 분포 p(w∣D)를 두고, 예측 시

- 를 근사. 즉, 단일 가중치 점추정 대신 가중치 불확실성을 반영.
- 효과:
- Epistemic 불확실성(“모델이 얼마나 확신할 수 있는가?”)을 정량화 가능
- 캘리브레이션(예측 확률과 실제 빈도 일치성) 개선
- 빈도론으로 하면?:
- 앙상블(여러 모델 학습) / 부트스트랩(샘플링 데이터셋으로 학습)
- 장점: 구현 쉽고 성능 강력, 병렬화에 적합
- 단점: posterior 해석이 부족, 샘플 효율성 낮음, 이론적 정당성 부족
- 트레이드오프:
- BNN: 원리적으로 깔끔, 이론적 해석 풍부. 하지만 MCMC/VI 등 근사 필요, 계산량이 마늠
- 앙상블: 실무에서는 더 자주 채택됨 (성능 vs 비용 균형)
(2) MC Dropout (Monte Carlo Dropout)
- 아이디어: 테스트 시 Dropout을 끄지 않고 그대로 유지, T번 추론
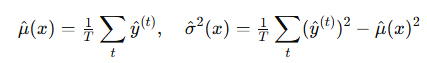
- → 평균과 분산으로 불확실성 추정
- 이론적 근거: Gal & Ghahramani (2016) — Dropout은 특정 prior에서의 베이지안 근사
- 장점: 추가 학습 없이 불확실성 얻기 가능, 비용 저렴
- 빈도론은: Dropout은 단순히 과적합 방지용 regularizer → 예측 분포 해석 불가
(3) 변분추론 (Variational Inference, VI) & VAE
- 목적: Evidence Lower Bound (ELBO) 최대화아이디어: posterior p(w∣D)는 보통 계산 불가능 그래서 단순한 분포 q(w;ϕ)로 근사
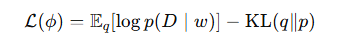
- Reparameterization trick: 샘플링을 미분 가능하게 만들어 SGD 최적화 가능
- 대표 응용: Variational Autoencoder (VAE)
- 잠재변수 z를 posterior 분포로 모델링
- 단순 생성기가 아니라 “확률적 표현 학습”이 가능
- 빈도론적은: EM 알고리즘, MLE 기반 접근 가능. 하지만 잠재변수 불확실성 전파가 약하고 생성모델 성능 제약
(4) 베이지안 최적화 (Bayesian Optimization, BO)
- 문제: 하이퍼파라미터 튜닝 = 블랙박스 함수 f(λ)최적화, 평가 비용↑
- 해결:
- GP(가우시안 프로세스)로 함수 분포 근사
- posterior 평균 μ(x), 분산 σ2(x)를 활용
- 획득함수(Acquisition Function)로 “다음 샘플 어디 찍을지” 결정
- Expected Improvement (EI), Upper Confidence Bound (UCB), Probability of Improvement (PI), Knowledge Gradient (KG)
- 장점: 적은 시도로 좋은 성능 → 샘플 효율 최고
- 빈도론은: Grid Search, Random Search, Hyperband/BOHB
- 단순, 병렬 확장 용이
- 하지만 불확실성을 반영하지 않아 탐색 효율 떨어짐
(5) 베이지안 강화학습 (Bayesian RL)
- 문제: 탐색-활용(Exploration-Exploitation) 딜레마
- 해결: 환경 동역학/보상에 posterior 유지 → Epistemic 불확실성 활용해 탐색
- 대표 기법: Thompson Sampling (Posterior Sampling RL)
- posterior에서 환경 샘플링 → 최적정책 수행
- 직관적·강력, regret bound도 준수
- 빈도론은: UCB 계열
- 신뢰구간 기반으로 낙관적 정책 선택
- 이론 보장은 좋지만, 확률적 다양성은 TS보다 떨어짐
- 실무 적용: Bootstrapped DQN = 앙상블 기반 TS 근사, ε-greedy/UCB는 빈도론적
(6) 캘리브레이션·의사결정
- Bayes 의사결정: 손실 L(y,y^)의 사후기대손실 최소화 = 비용 민감 환경에 최적
- 캘리브레이션:
- 베이지안 예측은 자연스럽게 과신(overconfidence)을 줄임
- 지표: Expected Calibration Error (ECE), Brier Score, Negative Log Likelihood (NLL)
- 선택적 예측(Abstention):
- maxyp(y∣x,D) → 모델이 “잘 모르겠다”는 판단을 내리고 거부/추가정보 요청
- 빈도론은:
- Platt scaling, Temperature scaling, Isotonic regression → 간단·효율적 보정
- Conformal Prediction → 분포 가정 없이 커버리지 보장 제공
- 차이: 베이지안 credible interval = “믿음의 범위”,
컨포멀 confidence set = “빈도적 보장” → 상호 보완적
5) LLM 맥락: 환각과 불확실성
- LLM 샘플링 제어(Temperature, Top-k, Top-p)는 출력 다양성만 바꾸는 기법 → posterior 불확실성 추정은 아님
- 불확실성 도입하려면:
- MC Dropout/앙상블로 predictive entropy·BALD 계산
- 결과 활용: 거부, 추가 evidence 수집(RAG), self-consistency 재시도
- 최근 논의 (“Bayesian in expectation, not in realization”):
- 평균적으로는 베이지안 근사 최적
- 그러나 특정 입력에서는 정보예산 부족 → 구조적 실패(환각) 발생
- 실무 팁:
- 정보예산 추정 → 부족하면 evidence 확장 or 예측 거부
- 결정 과정과 로그를 남겨 재현성과 감사성 확보
6) 언제 베이지안이 필요한가?
- 과한 경우: 데이터 엄청 많고, Epistemic 불확실성이 거의 사라지는 경우.
- 꼭 필요한 경우:
- 의료, 금융, 보안 등 고비용 오류 상황
- 데이터 희소, 도메인 쉬프팅
- 액티브러닝, 탐색 설계, 규제/감사 요구
접근 장점 한계/비용
| 베이지안 | posterior 통합(원리적), Epistemic 정량화, 캘리브레이션↑, 의사결정 이론과 결합 쉬움 | 계산비용↑, prior 민감성, 구현 복잡 |
| 빈도론+실용기법 | 단순·빠름, 앙상블/스케일링/컨포멀로 실무 성능↑, UCB·컨포멀 등 강한 보장 | posterior 해석력↓, Epistemic 표현 제한 |
✨ 마무리
통계를 배워온 인류의 진화는
호모 사피엔스 -> 빈도론자 -> 베이지안 으로 이어진다는 (베이즈 통계학 교수님의) Joke도 있습니다.
확률을 해석하는 방식이 이 정도로 달라지면서도 결국 두 관점이 공존하며 서로를 보완하는 게 되게 신기하다고 생각했어요.
빈도론은 “세상은 반복실험으로 이해할 수 있다”를 말하고,
베이지안은 “불확실성은 믿음과 데이터로 함께 다뤄야 한다”를 말합니다.
베이지안 통계학은 사실 이론으로만 배우면 처음엔 추상적으로 느껴질 수 있습니다.
하지만 ~ 불확실성을 다루는 언어라는 점에서 AI와 현실 문제 사이의 간극을 메워 주거든요.
데이터가 모자라고, 실수의 비용이 비싼 영역일수록 또 책임 있는 AI가 필요한 곳일수록 베이지안은 선택이 아니라 필수의 문법에 가깝습니다.