
https://arxiv.org/abs/2506.06382
On the Fundamental Impossibility of Hallucination Control in Large Language Models
This paper establishes a fundamental impossibility theorem: no LLM capable of performing non-trivial knowledge aggregation can simultaneously achieve truthful knowledge representation, semantic information conservation, complete revelation of relevant know
arxiv.org
llm 할루시네이션 시리즈 2번째 논문이에요.
이거는 꽤나 최신꺼고, 삼성 ai 센터에서 냈네요.
이 논문은 (1)편에서 쓴 “Hallucination is Inevitable” (학습이론 관점)보다 한 발 더 나아가, 환각 제어 자체의 불가능성을 수학적으로 정리한 연구입니다.
즉, 삼성 리서치 쪽에서 나온 강한 이론적 메시지: 환각은 제어 불가하며, 이는 단순한 데이터/모델 문제를 넘어선 “수학적 구조의 문제”라는 선언입니다.
요약(?, 이만큼만 읽어도됨)
핵심 요지
- 불가능성의 근원
- 이 논문은 환각이 단순히 엔지니어링 기술 부족 때문이 아니라고 말합니다.
- 원인은 정보 집합과 추론 과정의 수학적 구조 자체에서 비롯된 근본적인 한계라는 거예요.
- 즉, 더 많은 데이터, 더 큰 모델, 더 정교한 학습 방법을 써도 구조적 불가능성 때문에 환각은 반드시 남습니다.
- Trade-off 존재
- 모델 응답에는 세 가지 주요 속성이 있습니다:
- 진실성 (truthfulness)
- 지식 활용 (knowledge utilization)
- 응답 완전성 (response completeness)
- 이 세 가지는 동시에 최적화할 수 없고, 항상 서로 트레이드오프 관계에 있습니다.
- 예:
- “모른다”라고만 하면 진실하지만 → 지식 활용/완전성이 부족.
- 그럴듯한 답을 꾸며내면 완전하지만 → 진실성 위반.
- 모델 응답에는 세 가지 주요 속성이 있습니다:
- ‘관리해야 한다’는 관점
- 따라서 환각을 “완전히 없애겠다”는 목표는 잘못된 방향.
- 오히려 어떤 속성을 우선시하고, 어떤 속성을 포기할지 설계 수준에서 관리해야 한다는 제안을 합니다.
- 예: 안전-critical한 환경에서는 진실성을 최우선으로, 창의적 글쓰기에서는 완전성과 서사성을 더 중시.
- ‘건설적인 결과’라는 해석
- 단순히 “안 된다”라고 끝내는 비관적 결과가 아닙니다.
- 이 정리들을 통해 LLM 설계 시 필연적인 절충점을 정확히 특성화할 수 있다는 점에서 의미가 있습니다.
- 즉, “어떤 조건에서 어떤 속성이 깨질 수밖에 없는가”를 알게 되면 → 그걸 기반으로 더 합리적인 아키텍처/훈련 목표를 설계할 수 있음.
1. 논문에서 제기한 기존 방법론, 혹은 현실의 문제점
얘도 기존의 방법론들의 문제점을 앞의 inevitable이랑 비슷하게 생각하네요.
LLM의 환각은 이미 널리 알려진 문제지만, 대부분의 기존 접근은 경험적·기술적이었습니다.
- 데이터/학습 단계에서의 대응
- 더 크고 더 깨끗한 데이터 수집
- alignment 강화 (RLHF, RLAIF, DPO 등)
- knowledge distillation, continual learning
- 추론/생성 단계에서의 대응
- temperature, sampling 기법 조정
- retrieval-augmented generation (RAG)
- external verifier, self-consistency, chain-of-thought prompting
- 평가/벤치마크 단계
- TruthfulQA, HaluEval, HallucinationBench 등 다양한 데이터셋
하지~ 만 문제점은 명확합니다.
- 이런 방법들이 환각의 빈도를 줄일 수는 있지만, 완전히 제거하는 것은 불가능하다는 점이 계속 드러남.
- 기존 연구는 대부분 통계적·경험적 관찰 수준에 머물러 있었고, “왜 환각이 필연적으로 생기는가”에 대한 형식적 증명은 부족했음.
- 즉, 근본적 불가능성을 설명하는 이론적 프레임워크가 필요하다는 것이 이 논문의 출발점입니다.
2. 따라서 이 논문이 주장하는 내용
이 논문이 던지는 메시지는 단순하지만 무겁습니다.
“환각은 제어 불가능하다 !”
이를 뒷받침하기 위해 논문은 llm한테 요구되는 네 가지 핵심 성질을 제시합니다.
- Truthfulness: 모델 출력이 사실과 일치해야 함
- Semantic information conservation: 의미적 정보가 왜곡 없이 보존되어야 함
- Relevant knowledge revelation: 필요한 지식이 드러나야 함
- Knowledge-constrained optimality: 주어진 지식 제약 하에서 최적의 출력이어야 함
-> 불가능성 정리 (Impossibility Theorem):
위 네 가지를 동시에 만족하는 LLM은 존재할 수 없다. 즉, 어떤 지점을 잡으면 다른 지점에서는 환각이 불가피하게 발생합니다.
4. 그 방법론/실험 결과에 대해서:
이 논문이 조금 재밌는 점은, 하나로만 증명을 한게 아니라
세가지의 서로 다른 수학적 프레임워크로 동일한 결론(환각 제어 🙅♀️)에 도달했다는 겁니다.
4-1. Auction Theory (경매 이론)
: LLM을 '집단 지능'으로 보고, 내부적으로여러 가설과 토막 지식(agent)들이 후보출력을 내고, 그 중 일부가 최종 출력으로 선택되는 구조라고 가정합니다.
이걸 경제학에서 쓰는 경매 메커니즘으로 모델링합니다. 즉 각 agent가 '내가 가진 답변이 제일 옳다'라며 입찰을 하는 상황으로요.
여기서 중요한 정리가 Green-Laffont 불가능성 정리예요. (전 미시, 거시 둘다 B0라 진짜 기억에 없음)
- 이 정리에 따르면, 진실성, 사회적 효율성, 예산 균형 같은 조건을 동시에 만족하는 경매 메커니즘은 존재하지 않습니다.
- LLM 관점으로 옮기면, 사실성, 의미 보존, 관련성, 최적성을 동시에 보장하는 내부 선택 메커니즘은 불가능하다는 것 ..
즉, LLM은 여러 agent가 정보를 경매하듯 경쟁하는 지능 집단인데, 구조적으로 항상 왜곡(환각)을 낼 수밖에 업다고 설명하는 겁니다.
4-2. Proper Scoring Rules (확률 예측 이론)
: LLM의 토큰별 확률은 사실상 예측이라고 볼 수 있다.
(예: 모델이 '파리는 프랑스의 수도다' 0.9, '서울이다' 0.1 이렇게 확률을 할당한다고 하면, 이거는 확률적 예측)
통계학에서는 이런 확률 예측의 정직성을 측정하기 위해 proper scoring rules를 씁니다.
1. log score, brier socre 같은 것들이 있어요
2. proper scoring rule은 '참 분포를 정직하게 보고하는 것'이 최적 전략임을 보장합니다.
그런데, 집단적으로 결합했을 때는 문제가 생깁니다.
여러 scoring 결과를 합치면 jensen 불평등 때문에 정보 보존이 깨집니다.
"볼록 함수는 평균보다 분산을 좋아한다"
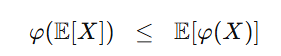
볼록 함수는 늘 저게 성립합니다.
무슨말이냐면, 곡선 위에서 평균을 먼저 내고 함수 적용하는 것보다 함수 적용 후 평균내는 게 더 크다는 의미.
** 요 llm/논문 맥락에서 보면
- llm이 여러 토큰/확률 분포를 합칠 때, 내부적으로는 log-sum-exp 같은 볼록 함수 연산을 사용합니다.
- 이 때 jensen 불평등(위의꺼)때문에, 개별 예측은 사실(f)를 보존해도, 집합적으로 평균을 내면 정보가 왜곡됩니다.
"정보를 모으는 과정에서 원래 의미가 그대로 유지되지 않고, 특정 방향으로 치우친 값이 나온다"는 걸 수학적으로 설명할 때 jensen 불평등이 등장합니다.

그러니까, 개별 예측은 정직할 수 있어도, LLM이 전체적으로 내는 결합된 출력은 왜곡될 수밖에 없습니다.
따라서 환각은 확률적 정직성을 강제해도 제거되지 않고, 오히려 수학적으로 불가피하게 발생한다는 결론
4-3. Transformer log-sum-exp 분석
: 이번엔 추상화말고, 실제로 트랜스포머 구조에 들어가서 분석합니다.
트랜스포머의 핵심은 attention인데 이건

이렇게 동작하죠.
1. 이때 softmax는 내부적으로 log-sum-exp 연산을 포함해서 ~ 정규화라하나? 그런걸 합니다
2. log-sum-exp는 수학적으로 "평균+정보 왜곡"을 만들어내는 성질이 있어요. 억지로 저 범위안의 값으로 매핑하는 함수니까요.
3. 그러니까. 여러 토큰/헤드에서 정보를 모을 때, 원래 의미가 그대로 보존되지 않고, 특정 방향으로 왜곡됩니다.
따라서 transformer 구조 자체가 정보 손실과 왜곡을 내포하고 있어, 저 모양상 환각을 피할 수 없습니다.
5. 한계점
이 논문은 강력한 메시지를 던지지만, 동시에 몇 가지 한계도 분명합니다.
- 이론적 모델링에 국한
- 수학적 불가능성 정리를 보여주지만, 실제 대규모 모델의 경험적 환각 패턴과의 정량적 연결은 제한적임.
- Ground truth 가정
- 논문은 결정론적 truth function을 전제.
- 그러나 현실 세계 지식은 모호성·불확실성·다중 정답이 존재할 수 있어, 실제 적용에는 간극이 있음.
- 실험적 뒷받침 부족
- log-sum-exp 등 구조적 분석은 설득력이 있지만, 다양한 실제 도메인에 걸친 대규모 실험은 부족함.
- 사회적·정치적 요소 미포함
- 환각 문제는 데이터 품질, 사용자 해석, 평가 체계 등 사회적 요인도 큰데, 본 논문은 이를 수학적 구조 문제로만 한정.
요약: 이 논문은 환각 문제의 수학적 본질을 규명하는 데 의의가 있지만, 현실의 LLM 사용 맥락 전체(데이터, 사회적 요소 등)를 모두 포괄하지는 못한다.
6. 마무리
앞서 봤던 논문보다 저에게는 ~ 좀 더 설득력 있고 흥미로운 논문이었어요.
막연히 이런 이유 때문일거다를 오목조목 설명해줬고,
조금만 뇌에 힘을 주고 읽어 보면, 결국 메시지는 동일합니다
" LLM이 여러 가능성을 결합하는 한, 평균 과정에서 왜곡이 생기고 환각은 피할 수 없다."
이거를 각각의 언어로 표현했어요.
'인공지능 공부' 카테고리의 다른 글
| 기깔나는 agent 만들기: LLM eval — 왜 평가는 모델보다 먼저 설계해야 하는가 (0) | 2026.02.05 |
|---|---|
| [논문 리뷰] (3) 왜 환각은 계속 남아 있는가? — Why Language Models Hallucinate (2) | 2025.09.12 |
| [논문 리뷰] (1) 왜 환각은 제어 불가능한가? — Hallucination is Inevitable: AnInnate Limitation of Large Language Models (1) | 2025.09.12 |
| [논문 리뷰] LLMs are Bayesian, In Expectation, Not in Realization랑 할루시네이션 (0) | 2025.09.04 |
| 인공지능에서 베이지안 통계학 — 불확실성을 다루는 언어 (3) | 2025.09.04 |